
The rise of generative AI has created exciting new possibilities for organizations, but one consistent challenge remains: how to effectively integrate enterprise knowledge into AI systems. Training or fine-tuning large language models with proprietary information is often prohibitively expensive. That’s why Retrieval Augmented Generation (RAG) has emerged as a popular and cost-effective solution.
What is RAG?
Retrieval Augmented Generation (RAG) combines the power of information retrieval with the capabilities of generative AI. Instead of retraining a model with proprietary data, RAG solutions retrieve relevant information from trusted repositories and feed it into the generative model at query time. This allows organizations to leverage their data in real time, while still taking advantage of the strengths of pre-trained language models.
Why Retrieval is the Hard Part
While the generative portion of RAG is relatively straightforward after inputting the correct data, the challenge is getting retrieval right. The accuracy and usefulness of any RAG solution depend heavily on the repositories of accessed information, the quality of the preprocessing steps, and the nature of the questions.
For example, if a law firm wants to use AI to summarize deposition transcripts, they might provide the model with the entire document. But if a procurement team wants to know, “What are the most common payment terms used across contracts for the last three years in this state?” retrieval suddenly becomes much more complex. Before the AI can provide a meaningful answer, the system must find, extract, and assemble information across many documents.
Managing Cost and Accuracy
Another critical factor is cost. Feeding too much information to the AI model can lead to “context bloat,” which is expensive and may reduce accuracy, increasing the risk of hallucinations. Limiting the tokens passed into the model is often more effective, provided retrieval ensures that only the most relevant data is selected. Preprocessing techniques can help, such as:
- Performing OCR on scanned content
- Summarizing document metadata
- Chunking large documents
- Storing content in a vector database
However, not all content within can be preprocessed efficiently. While working with one Verinext client, we had to move to a new solution to manage six terabytes of content. It was too large for traditional chunking and summarization methods, so retrieval began to resemble enterprise search, requiring scalable and intelligent approaches.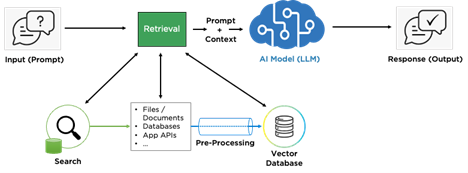
These types of search-based solutions can have their own set of issues. One pitfall lies in incomplete retrieval. For instance, Microsoft Copilot relies on Graph search to locate relevant documents. While fast, it may only return a small subset of documents – potentially missing key information. In the case of complex queries, such as the previous contract analysis example, this incomplete retrieval can undermine the value of the RAG solution.
Successful RAG implementations depend on a deep understanding of both the information sources being queried and the types of questions the AI must answer.
Verinext’s Approach
At Verinext, we help organizations design and implement RAG strategies tailored to their unique needs. From understanding repositories and data pipelines to crafting retrieval methods that balance accuracy, completeness, and cost, we ensure that clients maximize the value of AI solutions. Whether working with a few gigabytes of structured content or petabytes of unstructured data, Verinext guides clients in building RAG systems that deliver reliable insights at scale.
Related Posts:





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}